深入浅出Clickhouse: MergeTree引擎设计
LSM(Log-Struct Merge Tree)是大数据领域一种非常常见的技术, 例如LevelDB, RocksDB亦或是HBase都采用了LSM结构来完成存储系统的构架.
但你有没有发现, 这些大数据系统, 大多数都是KV方式的存储系统, 对外的接口也是以点查方式提供的.
虽然例如HBase的RowKey是全局有序的, 但是如果使用RowKey做大规模的范围查询, 它的整体效果可能还比不上在HDFS的文件上直接做过滤更有效.
基于以上的问题, 我们再回顾一下LSM的设计, 解答一下为什么LSM最适合点查, 然后再介绍Clickhouse基于LSM做了哪些取舍, 让MergeTree适合做范围的查询分析.
LSM树回顾
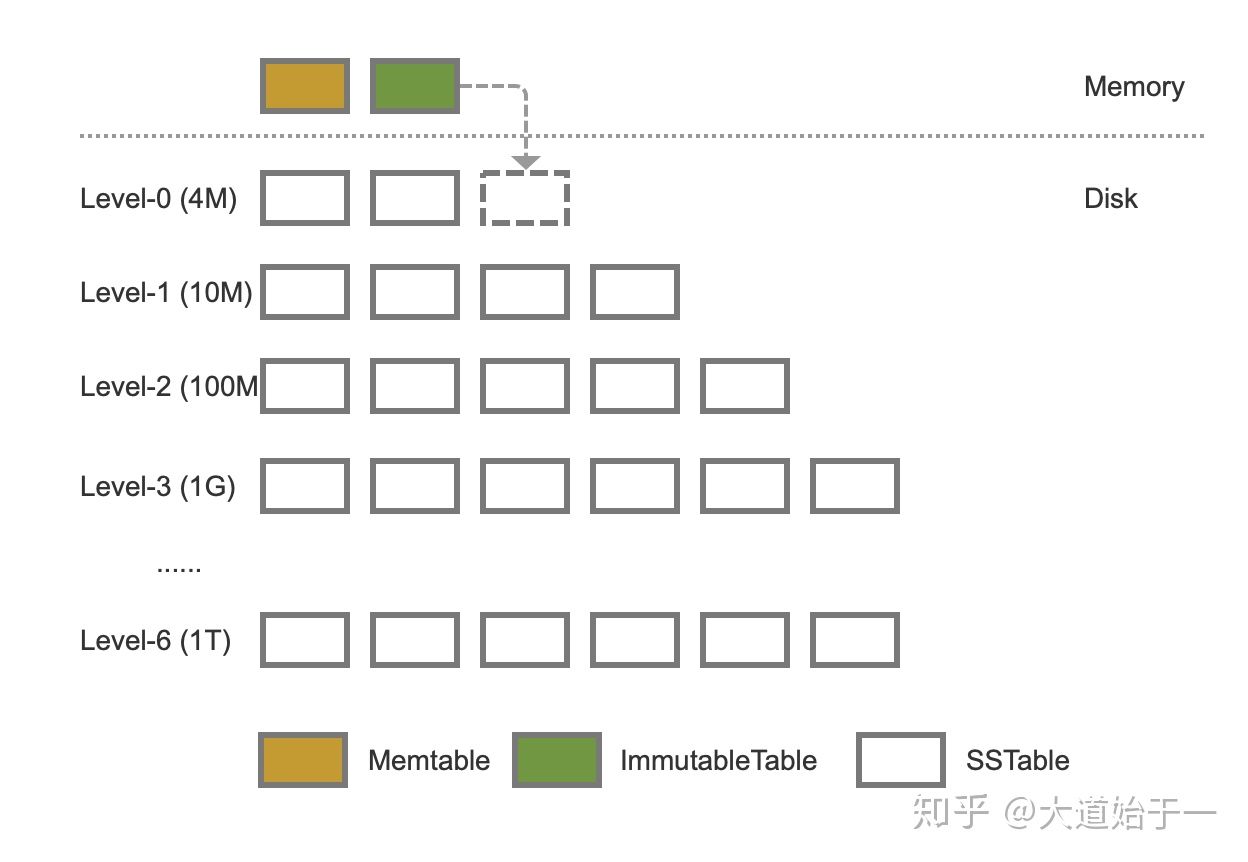
LSM的架构如上图所示, 数据先存放在Memory中, 然后通过一次的合并, 数据会固化到磁盘上.
为了防止每次合并都处理全部的数据, 因此LSM会将数据分层, 上一层比下一层小很多, 并且上一层的合并频率也比下一层多很多次.
由于需要合并去重的要求, 因此LSM树必须要指定一个类似主键之类的不重复的key.
另外一个点, 在Level-1以上, Key是在不同的文件块中, 是绝对不重复的, 而由于一般多是采用Range分区的方式, 我们可以称LSM树是Key键是全局有序且不重复的
当数据更新的时候, LSM只会将数据标记为删除, 或者更新一个数据的版本, 等到后续做数据合并的时候, 再做去重或者删除数据的动作
这就是所谓的写放大问题
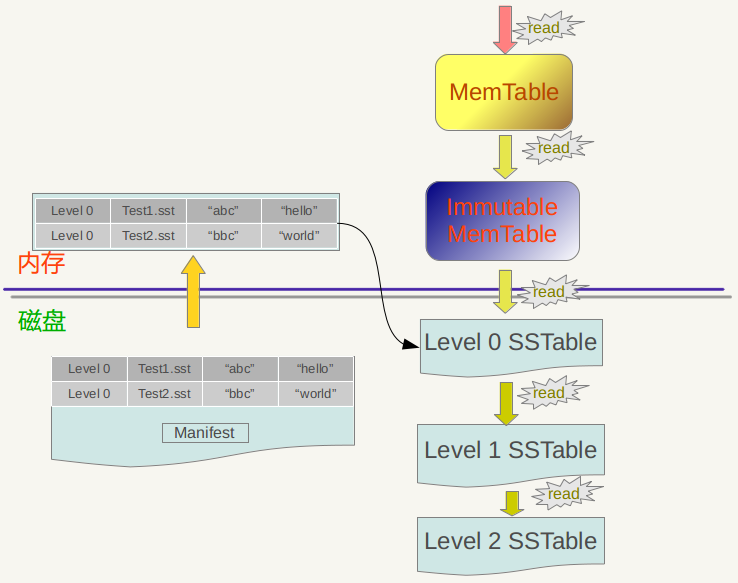
当读取数据的时候, 会先读取MemTable, 再读取Immutable MemTable, 最后在磁盘上一层一层读取文件, 直到最后读取到数据.
造成读放大的原因有两个点: 第一, 数据一旦没有命中, 就要往更深的层查找; 第二, 每个层中, 虽然因为全局有序, 点查只需要扫描一个SST文件, 但必须一次扫描整个SST文件.
总结一下, LSM的特点有:
- 必须有Key键, 且全局有序不重复
- 写入时, 一层一层写入, 更新删除只做标记
- 读取时, 一层一层读取, 读取效率在于命中率
然后再结合点查询的场景, 回答一下为什么LSM最适合点查:
- Key键全局有序且不重复, 这样查询时一下就能定位到对应的数据地址, 符合点查对对查询时延的要求
- 插入修改删除只是在Mem中添加数据, 这里就要求一次插入的数据不能太多, 不然内存存储不下, 就要开始合并, 会导致系统不稳定, 而点查一般一次只修改一行数据, 完美符合
- 读取数据时候, 时延在于命中率, 而点查询的热点效应明显, 主要在前几层能够命中, 整体读取的效率可以接受.
LSM树相对于B+树来说, 强化了Update和Delete的能力, 相对弱化的读取的能力
但是如果是范围查询, 就会出现:
- 一次更新数据可能是全部数据的20%以上, 例如修改某个字段的标号, 或者删除某些字段的数据
- 读取时给一个宽裕的过滤范围, 大多数的数据都能匹配中, 例如一个宽泛的前缀匹配
上面两个场景, 如果用LSM树的架构, 基本上是不可取的.
Clickhouse MergeTree设计
Clickhouse作为一个OLAP系统放弃了对于点查场景的支持, 而是主要面向范围查询的支持, 因此对于MergeTree做了大刀阔斧的修改.
对于Clickhouse来说, 没有单条的插入, 插入修改都抽象为对DataPart的操作.
DataPart在逻辑可以理解为批量的一组数据, 在物理上是磁盘上的一个文件夹,
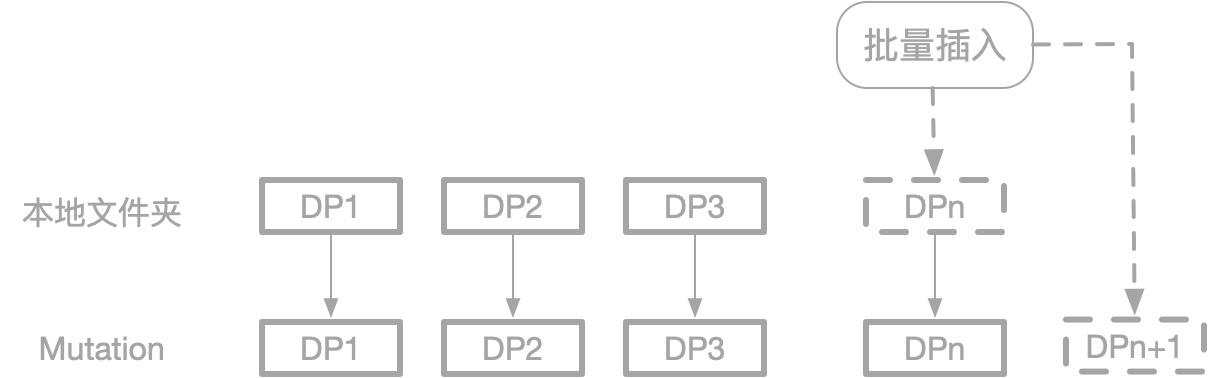
Clickhouse的数据组织, 如上图所示, 相比于MergeTree:
- 放弃了全局有序的约束, 只保证DataPart级别是有序的, 此时面对OLAP场景的批量插入, 只需要针对当前插入的数据做排序, 并插入为DP即可
- 放弃了多层的架构, 没有Memory层, 磁盘也只有一层. 在做Mutation(LSM对应Delete和Update)的时候, 也是DataPart到DataPart的转化
以上这两个设计的特点, 解决了写入和修改的场景, 但有一个明确的假设条件: 高吞吐的插入和 低频次大数据量的修改
此外这种方式, 比较实现列存模式(一个DP包含很行的数据), 因此天然比较适合OLAP, 而LSM比较适合行存, 一般用于OLTP.
但任何设计都有好坏, 一旦应用场景无法满足Clickhouse假设, 那么整体效果就会比较差:
- 插入批次小: Clickhouse由于不像LSM一样全局有序, 可以明确数据必然在一个数据块中, 因此查询时需要扫描分区裁剪后的所有DP, 因此CK会根据DataPart数量, 合并DataPart, 防止DataPart个数太多, 扫描性能太慢. 但如果插入批次小, 就会不停的触发Merge动作, 导致不必要的资源浪费, 因此都推荐在客户端攒批的方式写入
- 修改频次高: Mutation在Clickhouse被设计为一个非常重的操作, 因为需要处理大量数据, 但如果此时频次一高, 整个系统CPU马上就会上去
- 数据要求实时去重: 在Clickhouse设计中, DataPart数据间是没有关联的, 只有在Merge时才会产生关系, 但如果需要实时去重, 那么DP之间就会产生关联性(后写入的数据需要覆盖前面写入的数据), 不管后面如何优化, 这类场景的查询和写入都会比原生的差很多.
各种MergeTree
普通MergeTree
MergeTree表引擎主要用于海量数据分析,支持数据分区、存储有序、主键索引、稀疏索引、数据TTL等。MergeTree支持所有ClickHouse SQL语法,但是有些功能与MySQL并不一致,比如在MergeTree中主键并不用于去重,
1 | CREATE TABLE test_tbl ( |
ReplacingMergeTree
为了解决MergeTree相同主键无法去重的问题,ClickHouse提供了ReplacingMergeTree引擎,用来做去重, 但这个引擎依然有很多限制:
- 在没有彻底optimize之前,可能无法达到主键去重的效果,比如部分数据已经被去重,而另外一部分数据仍旧有主键重复;
- 在分布式场景下,相同primary key的数据可能被sharding到不同节点上,不同shard间可能无法去重;
- optimize是后台动作,无法预测具体执行时间点;
- 手动执行optimize在海量数据场景下要消耗大量时间,无法满足业务即时查询的需求;
1 | CREATE TABLE test_tbl_replacing ( |
CollapsingMergeTree
ClickHouse实现了CollapsingMergeTree来消除ReplacingMergeTree的限制。该引擎要求在建表语句中指定一个标记列Sign,后台Compaction时会将主键相同、Sign相反的行进行折叠,也即删除。
CollapsingMergeTree将行按照Sign的值分为两类:Sign=1的行称之为状态行,Sign=-1的行称之为取消行。
每次需要新增状态时,写入一行状态行;需要删除状态时,则写入一行取消行。
在后台Compaction时,状态行与取消行会自动做折叠(删除)处理。而尚未进行Compaction的数据,状态行与取消行同时存在。
因此为了能够达到主键折叠(删除)的目的,需要业务层进行适当改造
1 | -- 建表 |
CollapsingMergeTree虽然解决了主键相同的数据即时删除的问题,但是状态持续变化且多线程并行写入情况下,状态行与取消行位置可能乱序,导致无法正常折叠。
VersionedCollapsingMergeTree
为了解决CollapsingMergeTree乱序写入情况下无法正常折叠问题,VersionedCollapsingMergeTree表引擎在建表语句中新增了一列Version,用于在乱序情况下记录状态行与取消行的对应关系。主键相同,且Version相同、Sign相反的行,在Compaction时会被删除。
1 | -- 建表 |
SummingMergeTree
ClickHouse通过SummingMergeTree来支持对主键列进行预先聚合。在后台Compaction时,会将主键相同的多行进行sum求和,然后使用一行数据取而代之,从而大幅度降低存储空间占用,提升聚合计算性能。
值得注意的是:
- ClickHouse只在后台Compaction时才会进行数据的预先聚合,而compaction的执行时机无法预测,所以可能存在部分数据已经被预先聚合、部分数据尚未被聚合的情况。因此,在执行聚合计算时,SQL中仍需要使用GROUP BY子句。
- 在预先聚合时,ClickHouse会对主键列之外的其他所有列进行预聚合。如果这些列是可聚合的(比如数值类型),则直接sum;如果不可聚合(比如String类型),则随机选择一个值。
- 通常建议将SummingMergeTree与MergeTree配合使用,使用MergeTree来存储具体明细,使用SummingMergeTree来存储预先聚合的结果加速查询。
1 | -- 建表 |
AggregatingMergeTree
AggregatingMergeTree也是预先聚合引擎的一种,用于提升聚合计算的性能。与SummingMergeTree的区别在于:SummingMergeTree对非主键列进行sum聚合,而AggregatingMergeTree则可以指定各种聚合函数。
AggregatingMergeTree的语法比较复杂,需要结合物化视图或ClickHouse的特殊数据类型AggregateFunction一起使用。在insert和select时,也有独特的写法和要求:写入时需要使用-State语法,查询时使用-Merge语法。
1 | -- 建立明细表 |
描述和示例皆摘抄自阿里云