深入浅出Clickhouse: 索引结构设计
数据目录
当Clickhouse创建一个表, 会在配置文件path指定的路径下对应数据目录.
数据目录的路径为: {path}/data/{database}/{table}
1 | create table src ( |
例如上面的例子, 在default数据库上创建一个src的表, 如果path是在~/clickhouse/data目录, 那么整个目录为
~/clickhouse/data/data/default/src
当插入3次数据后, Clickhouse会再数据目录下, 每次都新建一个目录, 如下图所示, 这种目录在Clickhouse称之为DataPart

目录的格式为: partition_min_block_max_block_level
partition是分区的值, 根据建表的分区表示计算得来, 是一个规定的值; Clickhouse的目录并非按照分区规整的, 在数据目录下, 只有DataPart这层数据了, 也就是说, 通一个分区可能在多个DataPart上, 如上面的1_1_1_0和1_2_2_0min_block和max_block中的block是一个单挑递增的计数器, 插入3次后, 计数器就变成了3. 新的DataPart的min_block和max_block是一样的, 但在后续merge之后, 会变成一个范围值.level表示DataPart生命年龄, 当出现merge或者mutation操作时, level就会加1
举上面例子, 如果执行OPTIMIZE TABLE src , 强制表进行合并, 此时1_1_1_0和1_2_2_0两个DP会强制合并, 合并为1_1_2_1, 新DP的level变成了2, 而min_max_block由合并的DP的值确定. 另外合并只发送在同一个Partition内

合并操作, 并不会马上删除老的DP, 而是将其设置为
inactive, 读操作只会读取新的DP, 因此上图总共有4个DP, 过一段只会剩下两个DP
DataPart是存储数据的地方, 以上面的一个DataPart为例:
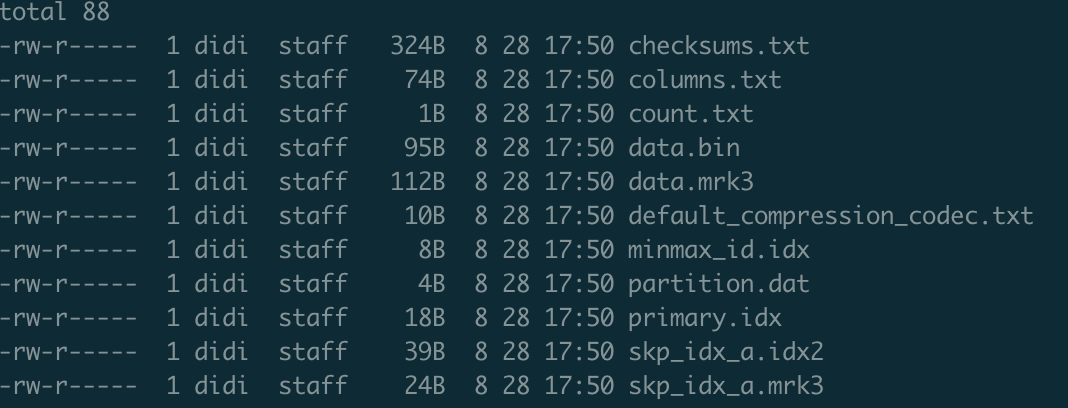
checksums.txt是整个DP的检验和columns.txt表示DP的列结构, Clickhouse将列字段放在DP级别的原因是, DP在做mutation的时候, 列可能会出现不一样data.bin存储着所有列的值, 称之为数据块data.mrk3是数据块的索引文件default_compression_codec.txt压缩方式minmax_id.idx分区文件的min_max索引partition.dat分区的值primary.idx主键索引, 或者成为一级索引skp_idx_a.idx2和skp_idx_a.mrk3跳数索引, 或者叫做二级索引.
当一个DataPart内数据量比较大的时候, data.bin会按照各自的列拆分为id.bin num.bin year.bin, 同理的还有data.mrk3
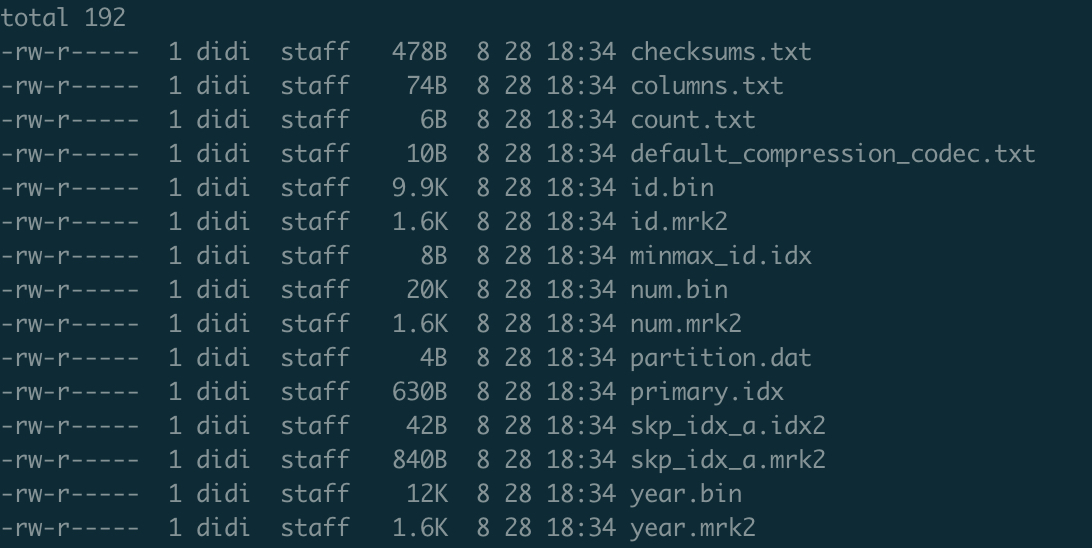
Clickhouse有两层索引, 一层为基于分区的索引, 这个在另外的文章中已经讲过, 它的目的是选择到具体的DP; 另外一层是基于数据排序的索引, 描述的是在一个DP内, 数据时如何组织以及被索引的.
数据索引
废话不多说, 直接上图, 依然以上面的建表语句为例, 与其中相关的是order by 和 partition by的语法.

在Clickhouse的一个DataPart中, 数据的逻辑分布可以想象成一个矩阵, 如图中的表示例数据方式陈列.
首先, 行与行之间的排序并非是固定的, 而是根据order by定义的方式排序, 例如案例中按照id和year排序, 那么num字段的位置也随着前面字段改变. 另外值得说的一点, 这个排序只是在DP内的, DP之间并没有顺序关系.
其次, 在物理上Clickhouse将按照每8192行数据切分整个矩阵, 将大矩阵切分为一个一个子矩阵, 在图中用编号来表示. 8192的数值由配置项index_granularity决定, 该配置为索引结构中最核心的配置.
Clickhouse的主键索引是一个稀疏索引, 它并不存储每一个行的数据, 而是存储每个子矩阵的第一个行数据, 因此8192行数据才会有一个索引值, 索引非常小, 对应的代价就是查找时, 需要用折半查找的方式来查询具体的编号, 复杂度为log(n)
主键索引可以是组合索引, 类似于mysql的组合索引, CK在查询时也必须满足最左匹配原则, 即查询时必须从最左的字段匹配起, 一旦有跳过字段方式, 索引将无法命中.
再次, Clickhouse对于非排序字段的查询, 设计了一种叫做跳数索引的二级索引方式, 名为跳数, 意思是并非记录每个编号内的索引, 而是选择一批编号进行计算, 例如图中是按照2个编号算一个跳数索引的方式.
跳数索引有三种: min_max,set和bloomfilter, 以min_max为例, 它存储的是两个数据块中的最大最小值, 此外跳数索引支持表达式, 但不是所有函数都支持, 支持的函数列表, 可以参考官网
跳数索引主要的目的为判断查询的数值是否存在, 如果不存在则跳过, 由于跳数索引是随机的, 因此的查询复杂度为n
其实不应该叫做
二级索引, 因为Clickhouse没有回表的动作,跳数索引选中数据块之后, 就直接通过暴力扫描的方式开始计算了.
最后, Clickhouse的数据存放在bin文件中, 这是真正的存储的地方. Clickhouse并非innodb类似的聚族索引将数据文件和索引放在一起, 而是数据文件和索引文件分开存储. 图中只列举了num.bin文件, 实际上还有id.bin和year.bin.
数据存储也并非按照8192行方式存储, 而是通过一个个数据块方式存储. 一个数据块大小为64K ~ 1Mb, 如果一个编号的数据太小, 就会将合并多个编号内的数据; 如果一个编号数据又太大, 就会拆分一个编号的数据. 而num.mrk文件实际上就是管理这层一对多,多对一关系以及维护存储上offset索引的数据结构. (具体的对应关系不展开了, 看图理解)
Clickhouse为什么不直接按照8192行的方式存储数据呢, 我个人的理解是为了最终数据块过大过小影响读取的稳定性. 当数据过小时, 多次查询索引和读数据, 会引起过多的IO. 当数据过大时, 会挤占过多的内存空间影响系统的稳定性.
总结一下
Clickhouse索引的特点为: 排序索引+稀疏索引 + 列式存储, 因此相应的Clickhouse最合适的场景就是基于排序字段的范围过滤后的聚合查询.
- 因为排序索引, 所有基于排序字段的查询会明显由于MR类型计算, 否则Hive/Spark这类动态资源的更优
- 由于稀疏索引, 点查询的效率可能没有KV型数据库高, 因此适合相对大范围的过滤条件
- 因为列式存储, 数据压缩率高, 对应做聚合查询效率也会更高.
与Hadoop列存结构的相比
以Parquet的为例, Parquet也会按照行列方式切分整个矩阵, 用Page或者RowGroup的概念实现, 这点跟Clickhouse一样

Parquet也有部分索引元数据, 能够实现谓词下推(Predicate PushDown)的能力, 因为元数据中包含整个块中的最大最小值, 因此能够方便的过滤数据块. 但是这个索引更像是CK中的跳数索引
但是由于Parquet是一个通用的存储格式, 因此它不能像Clickhouse一样定义排序字段, 因此也无法享受折半查找带来的查询优势.