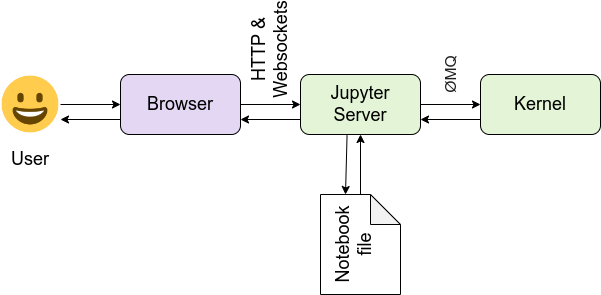
Clickhouse技术分享: 分区裁剪
本文代码截图, 基于2021-07-19的master版本
DataPart存储
1 | CREATE TABLE default.lineorder_local |
选了Clickhouse社区官方的SSB测试套的lineorder表为例, 他以toYear(LO_ORDERDATE)为分区键, 此时插入一些数据, 在Clickhouse DataPart级别的目录下, 会出现以下文件

其中跟分区相关的有两个: partition.dat和minmax_LO_ORDERDATE.idx
partition.dat存储的是Partition的具体数值, 对应Clickhouse的源码
1 | struct MergeTreePartition |
就是我们在system.parts表中看到的partition数值, 其中value的类型是Row, 对应表达式计算后的结果.