OLAP学习: 数学算法汇总
基数估计
通俗的话来讲, 就是求count distinct, 在公司内部有大量UV场景, 因此一款数据库对基数估计的支持是一个非常重要的功能.
一般计算基数, 通过分布式构造Hash表, 进行group by求解, 但该方式非常消耗内存和CPU, 无法满足大型互联网的要求, 因此有以下两个优化方向.
Bitmap
对于Long/Int型数据, 可以通过Bitmap方式来求解. Bitmap的存储和计算效率会明显优于Hash表.
普通的Bitmap结构比较清晰, 这里简单讲一下Roaring Bitmaps.
普通的bitmap为一个巨型数组, 而Roaring Bitmap会分为2级结构, 一级分桶, 总共有65535个(short最大值), 每个桶内则是short类型的bitmap, 可以存储65535个字节.
对于一个4字节的Int类型, 会分别取高16位和低16位, 也就是一个Int分裂为2个short类型.
前一个short表示index, 索引到具体的桶内, 后一个short在桶内的bitmap中操作.

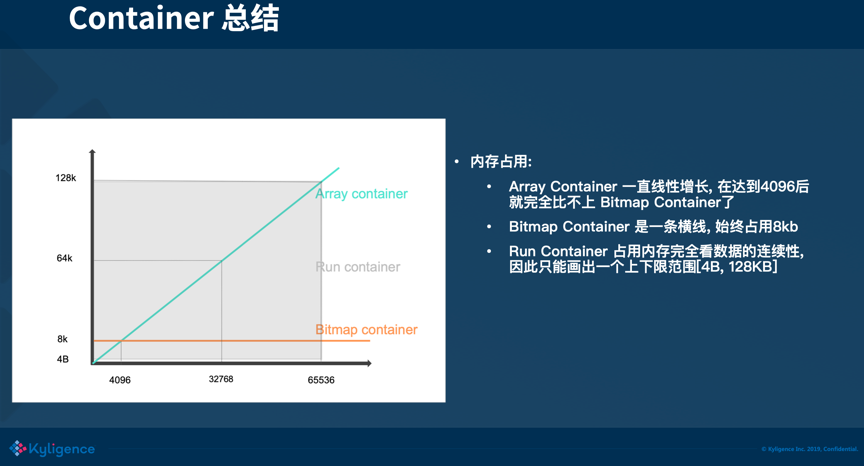
short类型的bitmap有三种类型:
- array[short]类型
- 普通bitmap类型
- RunLength类型
对于String类型数据, 可以通过一个KV字典, 将String转化为Int后再行求解.
HLL
以上面方法不同, HLL是一种近似计算基数的方式, 它是基于以下概率论的假设

在真实求解的时候, HLL构造一个桶列表(byte类型, 图中是64个), 取hash值后6位(64=2^6), 索引对应的桶位置, 然后取第一个除首位1之外1的值, 最后将所有桶的数值, 求取调和平均数. (图中Loglog算法为算数平均数, 误差较大)

百分数
T-Digest
准确说tdigest并非是百分数计算方法, 而是一种抽样方式, 通过引入质心的概念, 完成类似于KNN聚类效果.
聚类之后, 数据量比原来会小很多, 然后再调用精确计算百分位的函数quantile进行计算.
T-Digest有两种方式, 一种称为buffer and merge, 另一种称为cluster, 整个算法过程主要在平衡误差和计算效率的结果.
具体算法就不学习了, 有需要时, 再来看这个pdf
索引
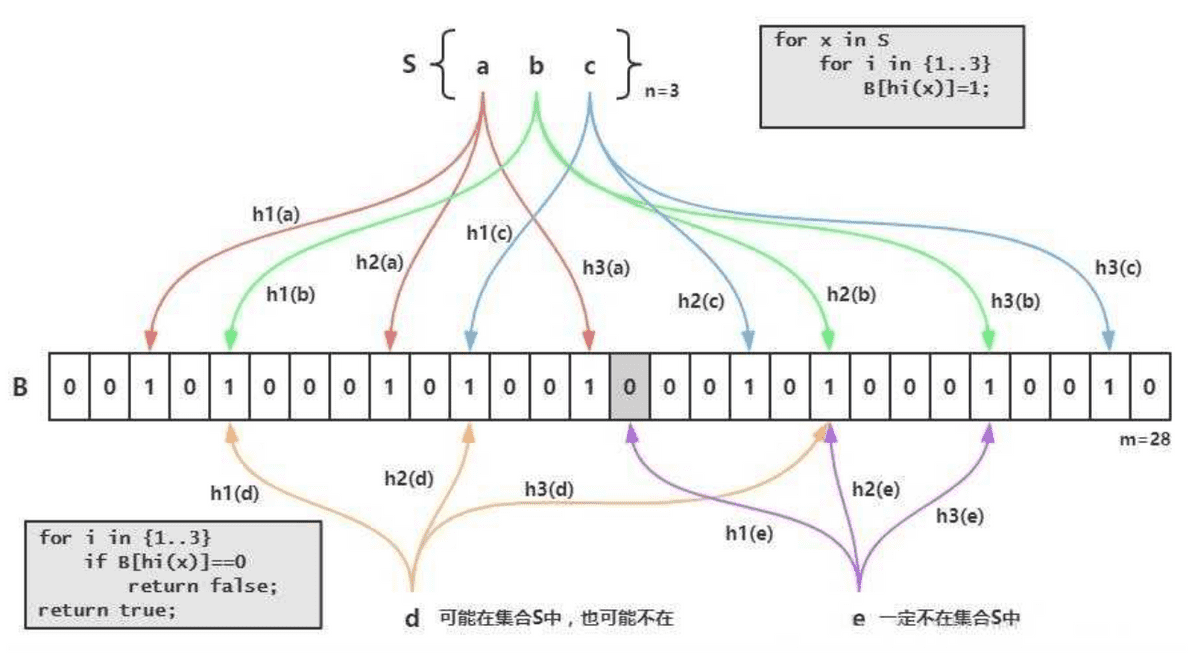
BloomFilter