迭代器引导的序列化惨案
背景
今天2月份左右GATK的4.1版本发布, 经过测试目前版本的准确率相对于单机版本也有版本提高, 具体数值见下表
| 单机GATK | Precision | Sensitivity | F-measure |
|---|---|---|---|
| SNP | 98.90% | 99.84% | 99.37% |
| INDEL | 97.20% | 96.22% | 96.71% |
| 分布式GATK | Precision | Sensitivity | F-measure |
|---|---|---|---|
| SNP | 98.91% | 99.84% | 99.37% |
| INDEL | 97.32% | 96.84% | 96.84% |
从图表上看, 虽然目前分布式GATK还是beta特性, 但是准确率已经和单机版很接近, 并且有部分还超越了.
| 对比项 | 单机版本 | 分布式版本 |
|---|---|---|
| 耗时 | 48H | 3.5H |
但是, 新版本的GAKT遇到一个严重的BUG, 使用ReadsPipelineSpark的时候, 如果使用hg38的Reference就必然出现StackOverflowError
Bug reported @ issues-5869
问题定位
这个问题有一个麻烦点就是, 从异常栈只能看出是序列化的时候出问题了, 但无法定位哪一行出现的问题, 因此需要首先定界出问题的代码行.
问题定界
一般来说, 定界问题有两种: Debug大法和Print大法.
Debug大法适合你已经对代码有一定的了解, 并有相应的测试用例支持, 这样做比较事半功倍.
而Print大法比较适合现在这种情况, 对GATK的源码不是很熟悉, 而且不知道如何构造简单用例复现问题的时候, 这个时候就在ReadsPipelineSpark的代码路径里面, 打满日志, 根据报错前的日志, 定界出错代码位置.
经过打印了解到, StackOverflowError发生在这个代码段之中
1 | private static Broadcast<Supplier<AssemblyRegionEvaluator>> assemblyRegionEvaluatorSupplierBroadcast( |
这里的大致逻辑是比较清楚的, 就是Driver将一部分信息通过Spark的广播机制发布到Executor里面, 这个会有序列化的动作.
序列化的对象有: hcArgs,header,taskReferenceSequenceFile,annotatorEngine这四个, 具体是哪一个呢?
这时候祭出Save-Load大法, 将其中某个值设置null, 再一次次的尝试, 最后发现taskReferenceSequenceFile设置为null的时候, 代码能走过这段逻辑.
当然SL大法在用的时候, 经常被自己的先验知识影响, 当时重点一直在怀疑
header和annotatorEngine这两个字段, 一直没想到Reference会有问题, 绕了不少弯路, 因此SL一次的时间还是挺长的.
问题定位f
上面已经定位出来是ReferenceSequenceFile这个类导致的问题, 那么这个类的哪一部分出问题了呢? 这个时候就要用到Debug大法.
构造一次测试用例:
1 | SparkContext sc; |
在UserDefinedReferenceSequenceFile里面不断将其中的字段加入进去, 最后发现以下代码片段导致整个StackOverflowError的问题:
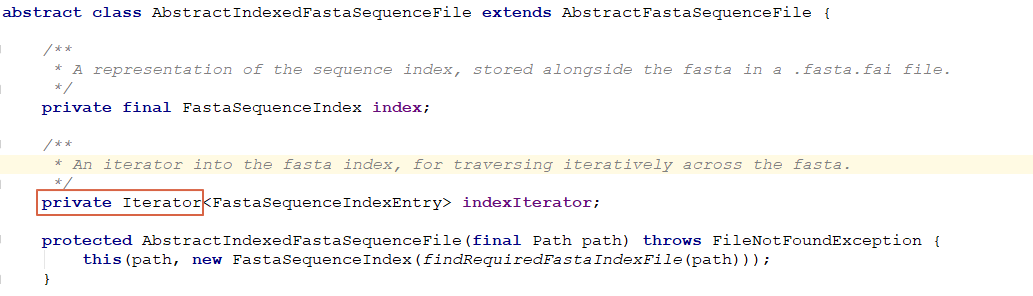
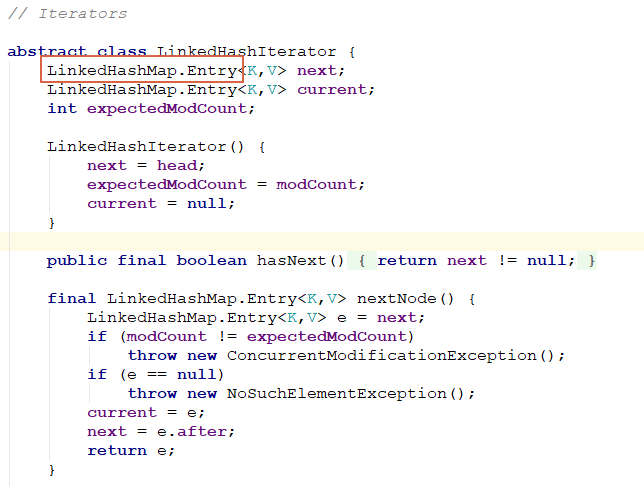
就是这个Iterator在序列化的时候, 会不断的递归遍历, 导致栈溢出.Iterator的实现为LinkedHashIterator, 里面LinkedHashMap.Entry为一个二叉树, 因此, 需要真实序列化的, 就会不断去遍历整个二叉树, 导致问题整个.

问题修复方案
社区已经有解决的方案了, 总体的方式就是不要在Driver加载Reference文件, 而是放在Executor, 这样就能免去序列化的步骤.
社区的问题目的是为了解决内存问题, 但实际上这个是序列化的问题. 此外实际运行的时候, 还有一个内存OMM的问题, 这个并不能够解决.
为什么这个问题值得记录
- 首先, 迭代器模式竟然会出现
StackOverFlowError, 这个真的没想到. - 其次, 对于陌生代码的定位方式记录一下.