并行计算模式
缘起
之前一直在做Spark相关工作, 主要就是做分布式计算相关的内容, 经常会听到一些BSP或者MPP等分布式模式的术语, 每次看过文章有些了解之后, 但是经常会忘记, 因此写个文章记录这些概念.
BSP/ASP/SSP
首先要明确的是, 这三个概念主要是为了处理机器学习领域迭代计算提出来的
BSP是指迭代过程之中, 必须等待前一轮的迭代全部才能进行下一轮, 每轮之间的等待,被称之为Barrier, 所以才叫做Barrier Synchronous Parallel
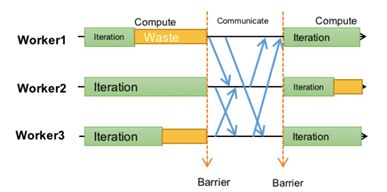
而
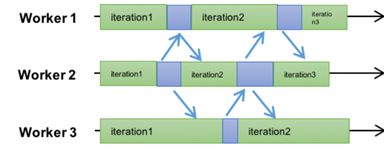
ASP: Asynchronous Synchronous Parallel是另外一个极端的方式, 任何一轮迭代绝对不会等待前面的迭代结果, 这个当然能解决BSP模型里面慢节点的问题, 但是它存在的问题就是速度不一,导致最后的梯度不收敛
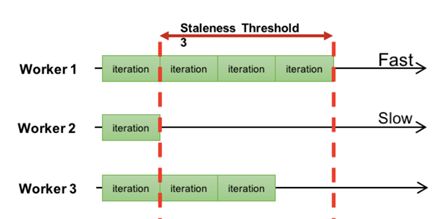
那么SSP: Stale Synchronous Parallel就是这两者的折中, 他有一个超参s, 表示最快的迭代和最慢的迭代之间的代差要小于等于S.
我们经常听说Spark或者MapReduce是一个BSP模型, 原因在于Spark的实际计算只有一轮迭代, 一轮迭代就需要直接出最终结果, 那么只有BSP才能正确计算完毕.
所以说, Spark是BSP的一种, 这种说明既对, 他确实有栅栏, 但也不对, 在于它主要描述分布式机器学习流程.
至于为什么机器学习那种多轮迭代为什么可以进行SSP或者ASP计算, 具体的数学原理可以查看如何理解随机梯度下降
SMP/NUMA/MPP
这三个概念主要出现在计算机体系结构之中, 主要将多核CPU如何实现并行计算的.
SMP:对称多处理器结构(Symmetric Multi-Processor)
NUMA:非一致存储访问结构(Non-Uniform Memory Access)
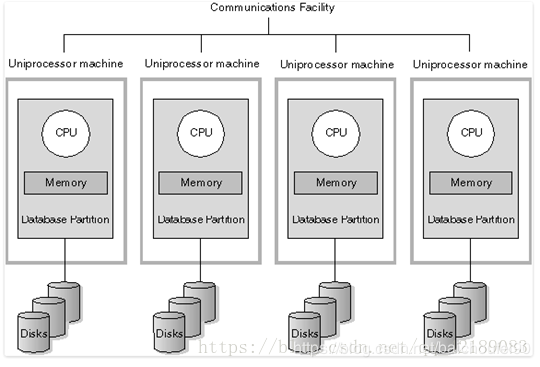
这两个经常在课文里面见到, 大学里面也学过, 大致的体系结构如下图所示:
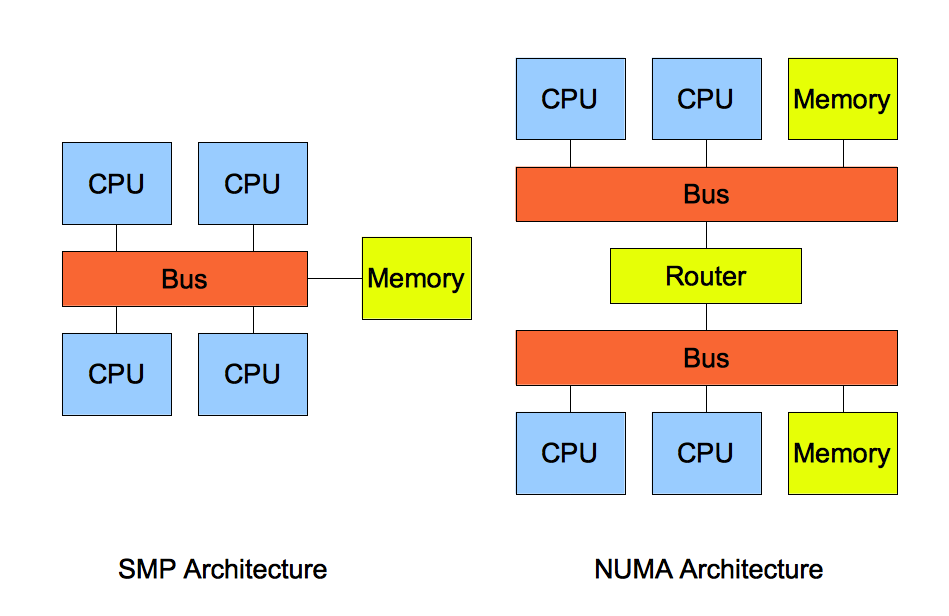
SMP和NUMA都是单机多核, MPP我理解就应该多台机器了
MPP:和NUMA不同,MPP提供了另外一种进行系统扩展的方式,它由多个SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而扩展能力最好,理论上其扩展无限制。
可能的示意图如下所示:
除了体系结构, 这三个概念还经常用于描述数据库的不同架构, 例如:
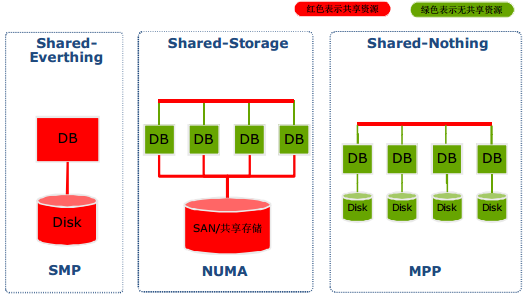
SMP是Shared Everthting的方式
NUMA是Shared Storage的方式
MPP是Shared Nothing的方式
按照这类分法, Spark是数据Shared Storage的方式, 因此数据放在HDFS可以共享获取.
MPP架构有如下特点:
- Share Nothing、节点之间数据不共享,只有通过网络连接实现的协同
- 每个节点有独立的存储和内存
- 数据根据某种规则(如Hash)散布到各个节点
- 计算任务也是会发布到各个节点并行执行,最后再将结果聚合到整体返回
- 用户使用时会看做整体
- MPP数据库(如GreePlum)往往优先考虑C一致性,然后是A可用性,最后考虑P分区容忍
- MPP架构目前被并行数据库广泛采用,一般通过scan、sort和merge等操作符实时返回查询结果
MPP架构劣势
- 很难高可用 -> 影响可用性和可靠性 因为数据按某种规则如HASH已经散布到了各个节点上。
- 节点数 =任务并行数 -> 影响扩展性 一个作业提交时,每个节点都要执行相同任务。而不像MapReduce那样做了根据实际开销进行任务拆分后散发到有资源的几个节点上。这一点大大影响了MPP架构应用的可扩展性。
- 每个客户端同时连接所有节点通信 -> 影响网络 MPP架构每个节点独立,所以客户端往往需要连接所有节点进行通信,这使得网络也成为瓶颈。
- 分区容错性差 前面提到过MPP主要考虑CA,最次才是P。那么一旦扩展节点太多后,元数据管理十分困难。
MPP 适用场景
- 集群规模100以内、并发小(50以下)
- MPP架构目前被并行数据库广泛采用,一般通过scan、sort和merge等操作符实时返回查询结果
MPP的典型架构
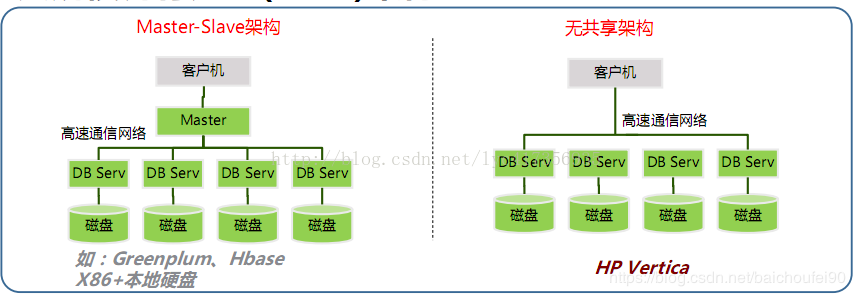
MPP数据库/Hadoop数据库
这个博客 介绍了MPP和Spark数据库的差别, 并提出现在MPP和Batch类数据库的融合, 文章写的很流畅, 读就是了.
另外特别的要提一下Impala, 这个系统之前做Spark SQL的时候, 和它对标过: 之前团队想要使用Spark SQL替代Impala. 但效果肯定不理想, MPP数据库的时延确实比Spark好太多 了.
这篇介绍Impala的文章不错, 可以好好看一下
这个章节, 回头再理理, 需要详细写一下
Poll/Push模式
这个是Shuffle处理的概念, 经常出现在流处理系统的概念表里面, 例如Kafka/Flink.
在Spark之中, Poll是指ReduceTask主动去拉Shuffle的数据, 这种模式容错比较好处理, 数据丢失之后主要重试计算就好了.
Push模式是指将MapTask主动将数据push到ReduceTask的节点上,但是我们实际上在MapTask时候比较难以估计ReduceTask位置, 尤其在节点丢失情况下, 所以要实现push模式, 编程量会很多.
而在Kafka之中, Push和Poll区别主要在于Consumer是主动获取数据, 还是被动接收数据.
这个概念还是比较容易理解的.
总结
总体的文章有点乱, 概念越看越模糊, 后续再优化吧.