Hexo使用技巧记录
新环境初始化
用于新环境的安装, 例如刚申请了一个电脑, 假设你配置完毕git和下载安装完毕NodeJs
执行下面的命令, 完成初始化命令
1 | git clone git@github.com:SaintBacchus/hexo.git |
如何实现置顶功能
首先安装hexo插件:
1 | npm uninstall hexo-generator-index --save |
然后在文章的Front-matter头部加入: top: true
用于新环境的安装, 例如刚申请了一个电脑, 假设你配置完毕git和下载安装完毕NodeJs
执行下面的命令, 完成初始化命令
1 | git clone git@github.com:SaintBacchus/hexo.git |
首先安装hexo插件:
1 | npm uninstall hexo-generator-index --save |
然后在文章的Front-matter头部加入: top: true
1 | 2021-12-08 10:20:52,561 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - JDBC executeBatch error, retry times = 1 |
Flink任务写入CK时, 出现以上异常, 并开始重试, 如果重试次数过多, 就会触发flink的重启, flink重启达到5次, 用户就会收到告警.
目前Flink重试的时候, 会造成Checkpoint期间的数据, 全部重新写入, 即能够保障AT_LEAST_ONCE语义.

在数据每次写入的时候, 都会调用该方法, 判断数据写入频率是否过快了, 如果太快了, 就会执行delay操作.
如何判断过快呢? 通过以下判断
1 | parts_count_in_partition >= settings->parts_to_throw_insert |
该文档写于2021年4月, 当时按照设计文档实现了RSS的原型(基于Uber的开源RSS), 但是后续应该人事调整, 我开始从事OLAP工作后,就不在开发RSS了.
目前公司内部有最大集群规模已经达到8000多台机器, 总共有近45万核, 1.23PB的内存, 其中每天有10万+个Spark的离线任务在运行.
目前团队正在将HiveSQL的任务都迁移到Spark引擎之上, 提升整体性能和资源利用率, Spark将承接越来越多的业务压力.
但随着Spark应用越来越多, 任务的稳定性受到了越来越多的挑战, 尤其是Spark Shuffle这块的问题, 一旦数据量超过一定阈值, 就会出现大量的Shuffle Fetch失败的情况, 由于Spark做了很好的重试机制, 因此有时候依然能跑出来结果, 但大量计算资源浪费在重试步骤之中; 而有时候因为失败太多, 导致整个App失败退出.
举个真实的案例, 下图是某业务运行的一个UI监控图, 从图中可以看到, 在Failed Stages里面出现了大量的FetchFailedException, 整个程序在不停的Stage重试, 而最后这个case由于失败过多整个APP失败了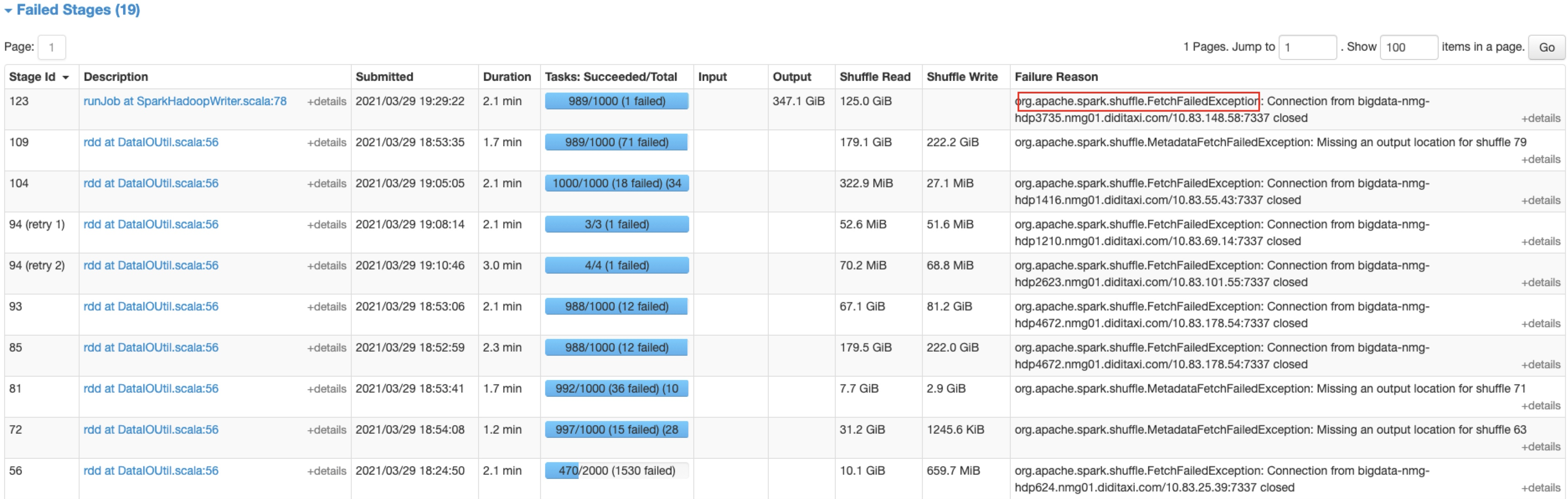
在上图中的19个Failed Stages都是由于
FetchFailedException造成的
该文档写于2021年1月
目前公司内部有3个集群, 最大集群规模已经达到8000多台机器, 总共有近45万核, 1.23PB的内存.
待补完…
目前集群上, 每天有60万个离线任务在运行, 其中Spark任务有10万个. 公司未来整体战略会将所有HiveMR的任务替换Spark任务, 今年将整个数据平台上的SQL任务基本上都迁移到Spark上.
整体的资源利用率得到了巨大的提升, 但随着Spark应用越来越多, 任务的稳定性受到了越来越多的挑战, 尤其是Spark Shuffle这块的问题, 总是让运维人员头疼不已, 一旦当天数据量超过历史, 会导致任务失败, 就需要隔离机器重新运行, 等业务量降低时候, 再释放空闲资源, 给整个团队巨大的运维成本.
我们分析Spark Shuffle的问题, 发现目前Shuffle机制存在如下几个问题:
代码主要在IStorage之中
1 | class IStorage |
排它锁lockExclusively的锁同时锁住alter_lock和drop_lock, 锁类型为写锁
1 | TableExclusiveLockHolder IStorage::lockExclusively(const String & query_id, const std::chrono::milliseconds & acquire_timeout) |
解决小批量数据写入时, 频繁写入dataPart, 导致磁盘繁忙的问题或者出现DB::Exception: Too many parts
具体可以参考这篇文档
并非binlog的模式, 数据flush后, 会清理wal文件
首先看写逻辑的入口, 在MergeTreeDataWriter::writeTempPart创建了一个MergeTreeData::MutableDataPartPtr的类型
1 | MergeTreeData::MutableDataPartPtr MergeTreeDataWriter::writeTempPart(BlockWithPartition & block_with_partition, const StorageMetadataPtr & metadata_snapshot) |
现在CK创建视图有2种初始化数据的方式
在 CREATE 语句中带上 polulate 关键字,会将执行时间点之前的底表的历史数据全部初始化到视图中。执行完成后的底表新数据也会进视图,但是执行过程中的数据会丢失;
在 CREATE 语句中不带 polulate 关键字,会将执行完成后的底表新数据会进视图,但是执行完成之前的数据都不会进视图;如果而后手工执行insert命令, 导入历史数据, 那么重复数据
先明晰一下MV更新的时候的时序图
下图中有4个角色: 插入语句执行者, 底表插入数据执行者, MV1插入数据执行者, MV2创建语句执行者
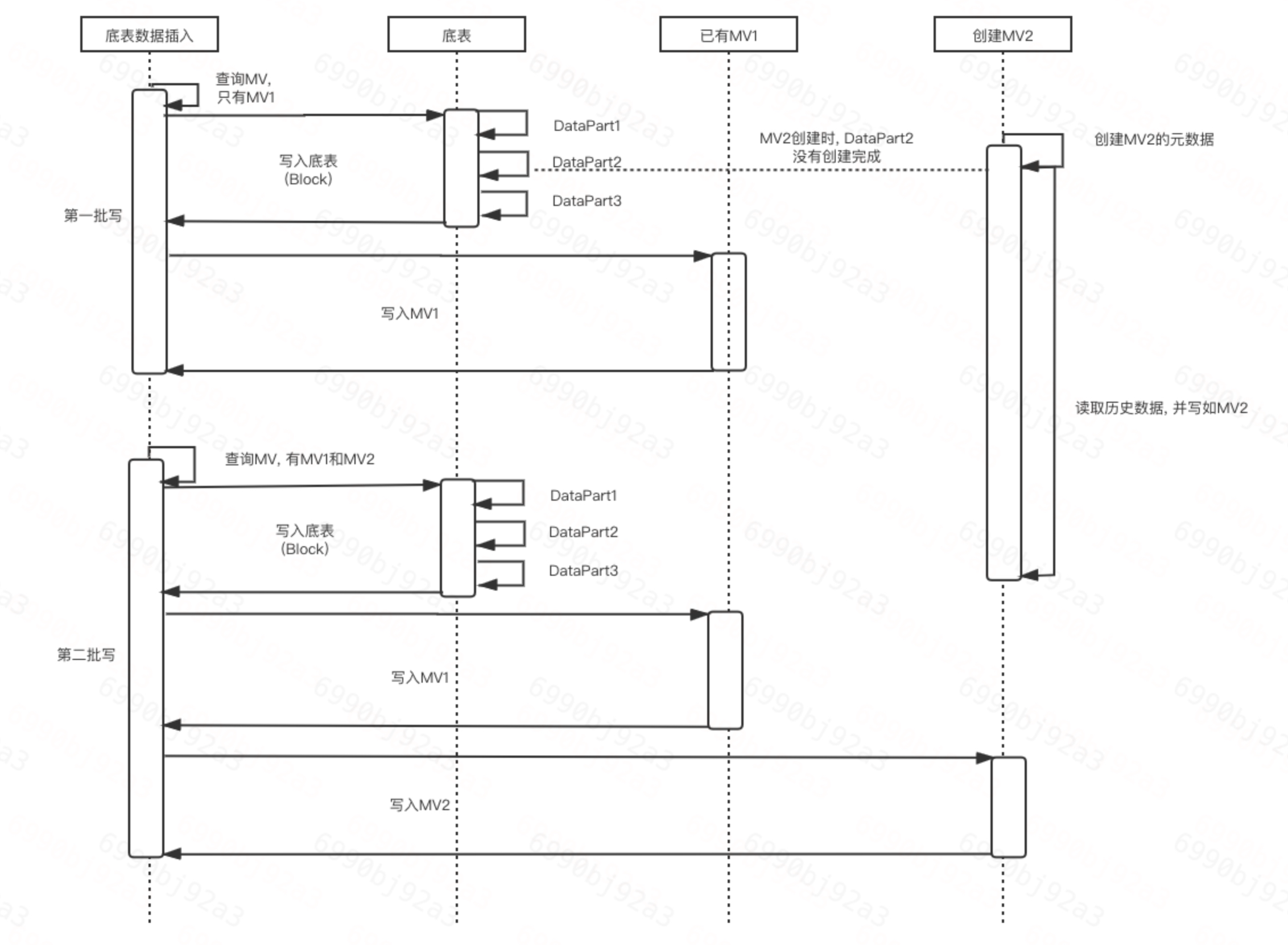
首先, 对于底表来说, 第一批写开始时, 因为MV2并没有被创建, 因此对于它来说, 只会给MV1主动推送数据, 相当于这批次的数据全部丢失了.
社区在Spark2.3版本之后的AdaptiveExecute特性之中就能很好的解决Partition个数过多导致小文件过多的问题.
通过动态的评估Shuffle输入的个数(通过设置spark.sql.adaptive.shuffle.targetPostShuffleInputSize实现), 可以聚合多个Task任务, 减少Reduce的个数
使用方式:
1 | set spark.sql.adaptive.enabled=true |
缺点:
Shuffle输出比, 为一个Shuffle任务中最后Output的数据量除以ShuffleRead的数据量的数值. 如果ShuffleRead为100GB, 而输出为1GB, 那么Shuffle输出比为1%. 如果这值比较低, 说明Task之中有很高强度的Filter功能. 这个数值太低会对系统产生比较大影响, 例如每个Shuffle块为
128MB, 如果输出比为10%, 那么最后在HDFS之中只有12.8MB, 就如会出现小文件问题. 因此动态执行功能并不会对此产生太大的效果. 现实中, 由于SparkSQL已经有比较高效的FilterPushDown功能, 因此这个比例不太太高, 在在20%以上.
通俗的话来讲, 就是求count distinct, 在公司内部有大量UV场景, 因此一款数据库对基数估计的支持是一个非常重要的功能.
一般计算基数, 通过分布式构造Hash表, 进行group by求解, 但该方式非常消耗内存和CPU, 无法满足大型互联网的要求, 因此有以下两个优化方向.
对于Long/Int型数据, 可以通过Bitmap方式来求解. Bitmap的存储和计算效率会明显优于Hash表.
普通的Bitmap结构比较清晰, 这里简单讲一下Roaring Bitmaps.
普通的bitmap为一个巨型数组, 而Roaring Bitmap会分为2级结构, 一级分桶, 总共有65535个(short最大值), 每个桶内则是short类型的bitmap, 可以存储65535个字节.
对于一个4字节的Int类型, 会分别取高16位和低16位, 也就是一个Int分裂为2个short类型.
前一个short表示index, 索引到具体的桶内, 后一个short在桶内的bitmap中操作.